
Uncovering Container Confusion in the Linux Kernel
TL;DR
We present uncontained, a framework to detect type confusion bugs originating from incorrect downcasting operations in non-object-oriented languages, which we call container confusion. In languages like C, object-oriented programming features are often mimicked by embedding structures as fields of other structures and downcast operations performed using the unsafe container_of() macro. uncontained leverages static and dynamic analysis to detect container confusion bugs in large codebases, such as the Linux kernel.
We introduce a novel sanitizer able to detect container confusion at runtime during fuzzing.
Based on the bugs we found, we generalize bug patterns and propose a novel static analysis framework to detect variants of those bugs across the entire codebase. Analyzing the Linux kernel, we found 89 container confusion bugs, responsibly disclosed them, and submitted 149 patches to fix all of them.
What are even containers in C?
As we all know C is not object-oriented and doesn’t have classes. But what if you want to have type hierarchies in complex code bases like the kernel?
You use structs as “classes” and embed them in each other to model class inheritance.
// parent struct
struct list_head {
struct list_head *next, *prev;
};
// child struct
struct goku_request {
...
struct list_head queue;
unsigned mapped:1;
};While C it is easy to create a pointer pointing to a specific field (&ptr->member), the opposite is strictly speaking undefined behavior as it needs to move the pointer out-of-bound of the original structure to obtain a reference to the outer child structure, i.e., downcasting.
Many large C code bases define their own macro to shift the pointer from the inner struct to the outer struct, called container_of() by taking the negative offsetof().
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - offsetof(type, member))); \
})A predominant example in the Linux kernel are data structures, such as linked lists. The list_head struct contains the pointers to the list_head of the next and previous elements in the list. Iterating over the list then accesses the next field of the embedded list_head and does a container_of() to retrieve the actual element.
#define list_for_each_entry(pos, head, member) \
for (pos = container_of((head)->next, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = container_of((pos)->member.next, member))
struct goku_request *iter;
list_for_each_entry(iter, list, queue) {
// executed for every 'goku_request' in the list.
...
}How widespread is the use of structure embedding?
We took the Linux kernel as a case study and built its type graph. Each node in the graph is a particular type in the kernel, which is connected to all the other nodes it can be downcasted to, through a container_of() operation.
Surprisingly, we found the type graph huge and extremely connected. We count more than 56.000 invocations of container_of() in the kernel, with almost 25% of all the types involved in some type hierarchy.
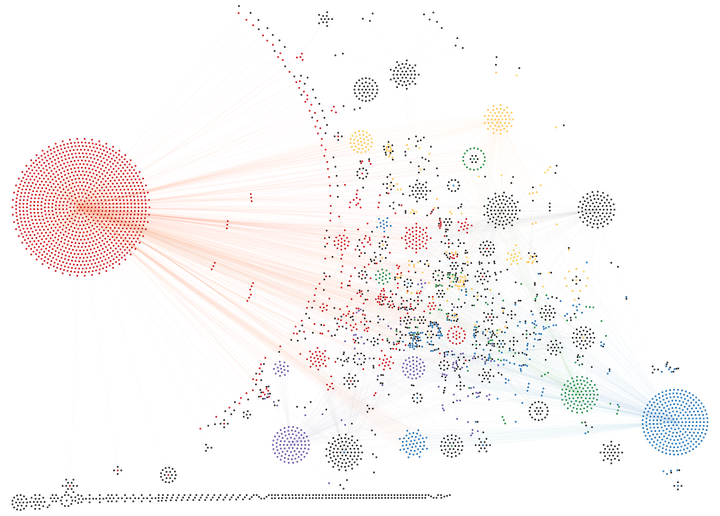
Looking at topological properties, 82% of the possible parent types can have more than one child type, making them subject to container confusion bugs, with 43% having more than ten possible child types.
Several types have hundreds (e.g., work_struct, hlist_hode, timer_list, qspinlock) or thousands (i.e., list_head) of possible child types that can inherit from them, making them extremely prone to container confusion bugs.
But where is the problem?
Developers need to specify container_of() the type you are casting to at compile time, with no way to check for correctness other than program semantics. Then, what happens if you pass a struct that is contained in a different type or not even contained at all? You create bogus out-of-bound pointers since there is no runtime checking!
But how likely is the code to have such bugs?
Let’s find out.
uncontained sanitizer
To check for container confusion bugs at runtime we avoid the need of precise runtime type tracking, which does not scale or is not even feasible on huge codebases as the Linux kernel.
Here the idea of our container confusion sanitizer is to check if an object “looks like” the correct object upon downcasting, by looking at its boundaries.
KASAN places redzones around objects to detect linear buffer overflows. We can repurpose those redzones to identify object boundaries! After a container_of() operation we check if the redzones in place match the redzones we expect for the type we are casting to.
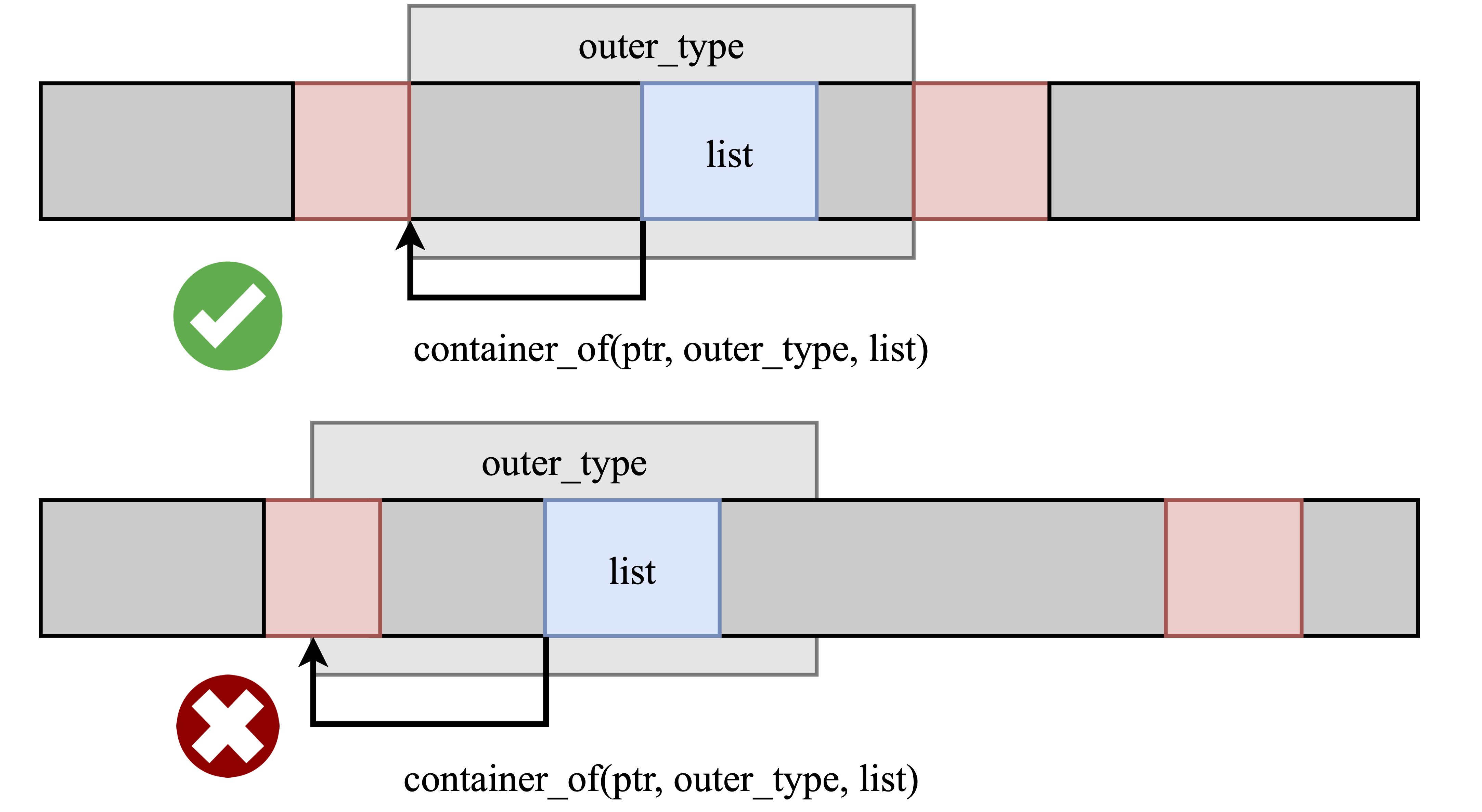
For more details on the design of our sanitizer, we refer to the paper.
With your own custom sanitizer, we fuzzed the kernel with syzkaller and discovered 11 bugs. However, dynamic analysis on the Linux kernel suffers from the inherent issue of a limited code coverage (due to many device drivers, etc.).
We analyzed the bugs and categorized them into five main patterns.
uncontained static analyzer
Based on the discovered pattern, we built static analyzers to detect variants of such bugs across the entire kernel code base.
Most patterns can be turned into a static information flow analysis problem, thus, we’ve built our own LLVM based framework for fast forward and backward information flow analysis. For one of the patterns we opted for extending an existing coccinelle script, written by Julia Lawall, since it does not require inter-procedural analysis.
With our static analyzer, again with more details in the paper, we discovered 80 additional bugs and 179 anti-patterns. We define anti-patterns as type confusions that due to implicit assumptions or current compiler behavior does not cause any actual corruption. We note that such code can easily be misunderstood, having a high chance of introducing bugs by changes such as e.g. upgrading the compiler or adding/reordering/removing struct fields.

Responsible Disclosure
We responsibly disclosed and proposed patches to the maintainers for all the bugs. We want to thank the maintainers for their time and positive feedback.
In total, we submitted 149 patches with 102 merged so far.
For our work, a total of 8 CVEs were assigned, two of the CVEs were discovered while manually analyzing code related code sections.
Code
The code for the sanitizer and the static dataflow analysis is available at https://github.com/vusec/uncontained.
The kernel framework, to simplify running custom LLVM passes for dynamic and static analysis, creating and running VMs for debugging and fuzzing is available at https://github.com/Jakob-Koschel/kernel-tools.
Paper
Acknowledgements
This work was supported by Intel Corporation through the “Allocamelus” project, the Dutch Ministry of Economic Affairs and Climate through the AVR program (“Memo” project), the Dutch Science Organization (NWO) through projects “TROPICS”, “Theseus”, and “Intersect”.