
Where many people thought that high-end servers were safe from the (unpatchable) Rowhammer bitflip vulnerability in memory chips, new research from VUSec, the security group at Vrije Universiteit Amsterdam, shows that this is not the case. Since prominent security researchers and companies have suggested that ECC provides pretty good protection [1,2,3], and exploitable bitflips on ECC memory are seen by many as the “unholy grail” for Rowhammer attacks, the new attack to reliably flip bits that completely bypass ECC protection is a major step forward in Rowhammer research.
What is this Rowhammer thing?
Four years ago (in 2014) researchers documented a bizarre vulnerability in DRAM memory chips which they dubbed “Rowhammer”: when many reads or writes access a particular memory location, a bit may flip (from 1 to 0, or from 0 to 1) in a completely different location. In the literature this is referred to as “hammering” one location, to flip a bit in another location. Initially more a curiosity than something many people worried about, the research community quickly learned how to weaponize the bit flips and completely compromise (“pwn”) many types of machine: PCs, smartphones, VMs in the cloud, etc. Moreover, the attacks turned out to be possible from Javascript, or even across the network on a remote server. Since the bug was present in many types of DRAM chip and patches are not possible for hardware defects, Rowhammer became a concern for, mostly, consumer devices.
But surely, ECC will solve this?
However, organisations that used more expensive server systems were less concerned. Here’s why: most high-end servers use ECC memory, a special type of memory that stores extra (redundant) information that the CPU uses to detect and repair these “bit flips”. In other words, if a bit flips, it is not a big deal, as ECC will fix it.
In fact, every time we gave a presentation about Rowhammer attacks, someone in the audience would ask: “But surely, ECC memory will stop this?” We now know the answer. “No.”
What makes ECC special?
ECC was originally developed to cope with bit flips due to cosmic rays and such—events that typically flip a single bit. Just like Rowhammer, but accidentally. In particular, ECC commonly adds enough redundancy to correct (repair) single bit flips in a word of, say 64 bits, and in the unlucky case that more bitflips occur, it can detect those up to a maximum, of say, two flips per word. Upon detecting two bit flips, it makes the program crash, as it cannot do a repair. This means that a single Rowhammer bitflip will not do anything, while two bitflips break the system. Only if you have three bitflips in the right places, will you be able to bypass ECC. However, how unlikely is that! After all, you need to get those three bitflips without accidentally getting two first and triggering a crash. Because of this, many considered ECC a good defense against Rowhammer—allowing maybe for denial-of-service attacks, but not a full compromise.
ECCploit shows that this is wrong.
We arrived at this conclusion when we set out to answer the question: How well does ECC really protect against Rowhammer?
So, what did we do? Details, please.
To answer the research question above, we first needed to fully understand how ECC is implemented. Unfortunately, this is not trivial. In general, CPU manufacturers omit details of ECC implementation. In addition, the closed nature of hardware makes our task even more difficult. Thus, we first reverse engineered several ECC implementations and showed their guarantees. This part of the work was pretty crazy and involved freezing memory chips and transplanting them (“cold boot attack”), sticking syringe needles into the sockets of memory modules to inject errors, and many other techniques besides. Long story short, after a year of probing and analyzing, we finally understood how ECC memory worked in detail.
Demo for the cold-boot attack
From knowledge to exploitation
Armed with this knowledge, we then proceeded to show that ECC merely slows down the Rowhammer attack and is not enough to stop it. Intuitively, the approach is fairly straightforward. Recall that we need three bitflips, while avoiding a situation in which only two bitflips occur. The first thing we discovered was a technique to ensure that at most one particular bitflip occurs in a memory word. The trick is simple: we make sure that all bits in the location that we hammer and the bits in the location that we want to attack are the same, except one. If the bits at the same position in the two locations are the same, no bitflip will occur. If they are different, the bit may flip. So we can independently try and flip first bit 1, then bit 2, then bit 3, etc. At first sight, that seems pointless. After all, ECC will simply correct that bitflip and it would seem as if nothing happened.
A timely trick
Phrased differently: one flip is no flip. However, this is not entirely true. What we found is that we can detect that a bit has been corrected by means of a timing side channel. Simply put: it will typically take measurably longer to read from a memory location where a bitflips needs to be corrected, than it takes to read from an address where no correction was needed. Thus, we can try each bit in turn, until we find a word in which we could flip three bits that are vulnerable. The final step is then to make all three bits in the two locations different and hammer one final time, to flip all three bits in one go: mission accomplished.
FAQ
OK, so how fast is the Rowhammer attack on an ECC system?
It depends on the exploitation method used and how easy is to find bit flips. In theory, the PTE based attack will take around 32 minutes to find exploitable bit-flips when the bit-flips are directly observable (see CVE-2018-18905 and CVE-2018-18906). It can take up to one week if we use the side channel of the signal in a coarse grained (or noisy environment).
Should I stop using ECC?
No. ECC is a reliability mechanism! However, ECC cannot stop Rowhammer attacks for all hardware combinations. If the number of bit flips is sufficiently high, ECC will only slow down the attack.
Where is ECC implemented?
In this work we reverse engineer the ECC engine (function) that is implemented in the Memory Controller. This usually sits on the same die as the CPU. The control bits are stored next to the real data, often in a separate memory chip on the DIMM.
How is ECCploit working?
Our goal is to cause silent corruptions — errors that ECC cannot correct and cannot detect. We do this in two steps:
- find bit flips that are corrected by ECC. We can detect these flips with the side channel that we discovered.
- combine these bit flips such that ECC cannot corrected and cannot detect the bit flips.
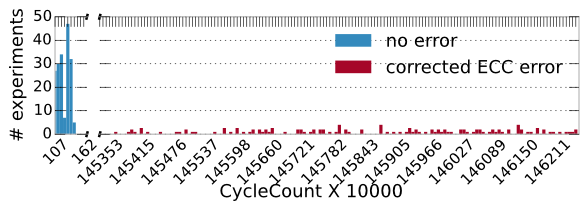
Wow an ECC side-channel!?
Yes, when ECC detects (and corrects) errors we observed a timing difference between “Error” and “No Error” case. This event is measurable by performing memory accesses in a tight loop. CVE-2018-18904 tracks this side-channel. For example, on some systems, this difference can be up to 1000X between the two cases.
What’s up with the syringe needles?
To reverse engineer the ECC, we propose several techniques based on fault injection. For example, a very cost efficient way to cause faults on the memory bus, is to short circuit data signals with a custom built syringe needle probe on the memory bus. We describe these techniques in our paper, but here’s a picture of the setup (we omitted the DIMM).

Demo for the fault injection
Do you need physical access for ECCploit?
No. While we use several techniques that require physical access to reverse engineer the ECC engine, the attack works via an unprivileged remote shell. The gist is that an attacker gathers information about the ECC engine in his own secluded/controlled environment that is similar to the target system. Then, using this information, they can launch the attack.
I provide a cloud service, what should I do now?
Make sure that the error reporting software stack is working and that the system safely reacts to ECC errors. The handling of ECC errors in software problem was already mentioned by Mark Seaborn and Dan Kaminsky. On recent platforms, the ECC engine logs the errors at firmware level. On the long run, you should phase out memory/setup that is susceptible to Rowhammer. Remember, this attack combines multiple correctable errors to trigger undetectable (silent corruption) errors.
What about DDR4?
While in our experiments we focused on DDR3, we believe that the side-channel introduced by the error correction is observable even on DDR4.
Is TRR a good defense for Rowhammer?
Target Row Refresh, (TRR) may deter Rowhammer based attacks. We lack data on the adoption status of TRR though. TRR is a feature that, if it is available on the memory chip, then the firmware (BIOS) must explicitly enable it at boot time. This feature is non-standard. In fact Rowhammer induced errors were reported on DDR4 (non-ECC).
How vulnerable are the DDR3 DIMMs?
It is hard to give an exact number, as this number will vary across generation (die revision) of memory, manufactureres and memory controller version. However, on one of our tested DIMM we found that 0.06% of the agressor-victim rows candidates would cause silent memory corruption. In addition, using the data base of bit flips of Tatar et al. up to 2% of all bit flips would go undetected on one of their DIMM.
What hardware did you use for testing?
We used four setups: AMD-1, Intel-1, Intel-2 and Intel-3.
The Intel-1 setup uses the Intel Xeon E3-1270 v3 CPU built on the Haswell microarchitecture and a Supermicro X10SLL-F motherboard (BIOS version: 3.0a).
Our next setup, AMD-1 contains the AMD Opteron 6376 CPU that is part of the Bulldozer Family 15h microarchitecture. We place this CPU on the Supermicro H8SGL-F motherboard with the BIOS: 5.925, version: 3.5a).
Intel-2 is the HP Proliant DL360p Gen8 Server that uses the Intel Xeon E5-2650 v1 (Sandy Bridge) CPU with default configuration of BIOS (version P71).
Lastly, Intel-3 is the SuperServer 1026GT that uses the Intel Xeon E5-2620 v1 CPU (Sandy Bridge) and a Supermicro X9DRG-HF motherboard with BIOS version 1.0c.
In our experiments we tested several memory modules from different manufacturers. We confirm a significant amount of Rowhammer bit flips in a DIMM similar to the one on which Brasser et al. reported the highest successful exploitation rate.
Finally, we refrain publicly naming one memory manufacturer or another.
How about software defenses?
It is very hard to protect against a hardware flow in software especially when we lack a full understanding of the Rowhammer phenom. However, researchers proposed several software defenses that generally incur a high memory or run-time overhead. The error correcting concept can be useful in this domain as well. In fact, we recently proposed a defense that builds on top of software ECC.
You don’t have a logo, do you live under a rock?
No. But here’s some nice artifact that we generated based on one of the ECC implementation that we reverse engineered.

Can I get DDR3 DIMMs that are Rowhammer-free?
CPU manufacturers usually test their compatibility with some DIMMs. However, we found some of the memory chips tested by them to be susceptible to Rowhammer. In addition, server vendors provide guidelines on how to chose the DIMMs. Allegedly, they perform extra testing of these memory-CPU combinations. We lack any information weather or not server vendors actively test their systems against Rowhammer and if they do, how effective/accurate is the test? Nevertheless, they acknowledge the problem and push firmware updates that increase the refresh of RAM in order to defend against Rowhammer. Therefore, choosing hardware compliant with the CPU manufacturers’ and server vendors’ guidelines and performing extra testing, is a safe approach.
Is there a CVE?
We responsible disclosed our findings to affected parties. The disclosure process was coordinated by the National Cyber Security Center (NL). CVE-2018-18904 tracks the timing side-channel of the error correction. Information about operating systems’ drivers of several Linux distribution can be found in CVE-2018-18905 and in CVE-2018-18906.
Papers
Acknowledgements
This work was supported by the European Union’s Horizon 2020 research and innovation programme under grant agreements No. 786669 (ReAct) and No. 825377 (UNICORE) as well as by the Netherlands Organisation for Scientific Research through grants NWO 639.023.309 VICI “Dowsing”, NWO 639.021.753 VENI “PantaRhei”,
NWO 016.Veni.192.262, and NWO 628.001.005 CYBSEC “OpenSesame”. The public artifacts reflect only the authors’ view. The funding agencies are not responsible for any use that may be made of the information they contain.